On 18 May 2025, I gave a presentation at Badji Mokhtar – Annaba University as part of the AI Masters Challenge, an event organized by the House of AI on the occasion of Students’ Day. The challenge brought together student teams competing to determine who could best use AI tools for bibliographical research, finding, analysing, and summarizing book content as efficiently and accurately as possible.
This post summarizes what I covered, the tools I introduced, and the prompting framework I walked students through. Whether you are a student, a researcher, or simply curious about practical AI use, the techniques here apply well beyond a single competition.
The Problem With How Most People Use AI for Reading
Most people approach AI the way they would a search engine: they type a vague question and expect a useful answer. When it comes to books, this usually produces generic, shallow output that adds little value over reading the back cover.
The core message of my presentation was simple: the quality of what AI gives you is determined almost entirely by the quality of what you ask it. The tools matter, but the prompt matters more.
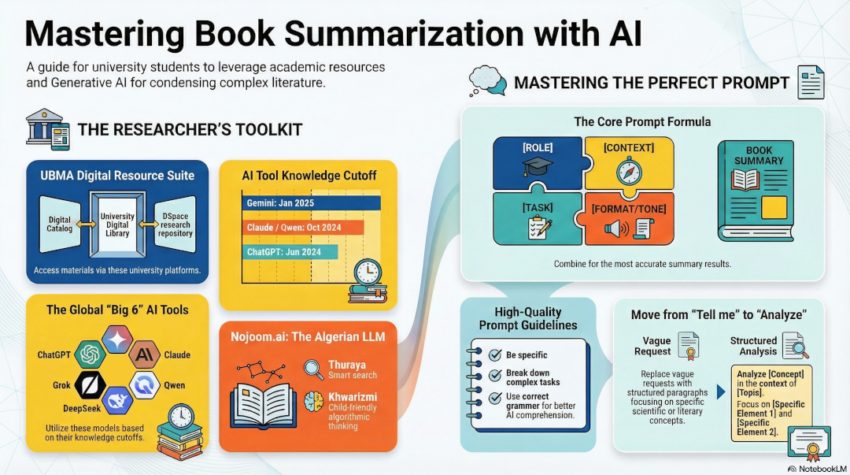
The Tools
I introduced students to a range of AI assistants currently available, grouped by their origin and strengths:
General-purpose LLMs:
- ChatGPT (OpenAI): the most widely known, strong at structured academic summaries and following detailed instructions.
- Claude (Anthropic): particularly strong at handling long texts, nuanced instructions, and maintaining a consistent tone throughout a summary.
- Gemini (Google): well integrated with Google’s ecosystem, useful when working across documents and search simultaneously.
- Grok (xAI): conversational and direct, with strong reasoning capabilities.
- Qwen (Alibaba): a capable multilingual model with strong performance in both Arabic and English.
- DeepSeek: a high-performing open-weight model, increasingly popular in academic and research contexts.
Algerian LLM
- Nojoom.ai: an Algerian large language model built around Arabic, with tool names drawn from Arabic cultural heritage. I highlighted this specifically as a locally relevant option students should be aware of and support.
I also covered the Central Library of UBMA’s own digital catalog, which students can use to locate books and resources before turning to AI for summarization and analysis.
The UBMA Library as a Starting Point
Before reaching for an AI tool, students need to find the right book. I walked through the Central Library’s online catalog as the first step in any bibliographical research workflow, identifying the source, confirming its relevance, and then using AI to process it efficiently. AI is most powerful when it is directed at a well-chosen source, not used as a substitute for finding one.
Prompt Engineering
This was the centrepiece of the session. I introduced students to a three-level prompting model using one of my favourite books as a concrete example: Physics of the Impossible by Michio Kaku.
Level 1: The Bad Prompt
“Tell me about Physics of the Impossible.”
This is what most people start with. The result is a generic paragraph that could apply to any popular science book! no structure, no academic value, no specificity.
Level 2: The Better Prompt
“Summarize Physics of the Impossible by Michio Kaku in 5 sentences.”An improvement: the AI now has a clear format and scope. The output is concise and usable, but still lacks context about purpose, audience, or depth.
An improvement: the AI now has a clear format and scope. The output is concise and usable, but still lacks context about purpose, audience, or depth.
Level 3: The Effective Prompt
“You are a university student preparing a short academic presentation on futuristic science concepts. Summarize Physics of the Impossible by Michio Kaku, focusing on three scientific ideas that were once considered impossible. Write in formal academic tone and limit the summary to one structured paragraph.”
This prompt gives the AI a role, a focus, a format, and a tone. The output is structured, academically appropriate, and directly usable. The difference in quality between Level 1 and Level 3 is not subtle — students saw it immediately when we ran all three prompts live.
The key elements of an effective prompt can be remembered as four questions:
- Who are you asking the AI to be? (role)
- What exactly do you want it to produce? (task + format)
- Which part of the source matters most? (focus)
- How should it sound? (tone + constraints)
The Live Demo
Students then tested this framework themselves, each choosing a book relevant to their competition topic. Rather than giving them a fixed text to work with, we let them apply the three-level model to their own material in real time. The shift in output quality was visible, and more importantly, students understood why the better prompts worked, not just that they did.
Key Takeaways
AI tools are now capable enough to meaningfully support academic reading and research. But they are not automatic. Using them well requires the same critical thinking skills that good research has always demanded: knowing what you are looking for, why it matters, and how to ask the right questions.
Prompt engineering is not a technical skill reserved for developers. It is a literacy — and one that every student doing bibliographical work today should develop.
Resources
Acknowledgements
My thanks to the House of AI for organizing the event, the Central Library for supporting student learning, and all AI Masters Challenge participants for their energy and curiosity.